Die kontinuierliche gleichmäßige Verteilung
Contents
Die kontinuierliche gleichmäßige Verteilung¶
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import uniform
Die Gleichverteilung ist die einfachste Wahrscheinlichkeitsverteilung, aber sie spielt eine wichtige Rolle in der Statistik, da sie bei der Modellierung von Zufallsvariablen sehr nützlich ist. Die Gleichverteilung ist eine kontinuierliche Wahrscheinlichkeitsverteilung und befasst sich mit Ereignissen, deren Auftreten gleich wahrscheinlich ist. Die kontinuierliche Zufallsvariable \(X\) gilt als gleichmäßig verteilt oder hat eine rechteckige Verteilung auf dem Intervall \([a \ \),\( \ b]\). Wir schreiben \(X \sim U(a \ \),\( \ b)\), wenn seine Wahrscheinlichkeitsdichtefunktion gleich \(f(x)=\frac{1}{b-a},x \in [a \ \),\( \ b]\) und ansonsten gleich \(0\) ist (Papula [2016] s.331).
Die folgende Abbildung zeigt eine kontinuierliche Gleichverteilung \(X \sim U(-2 \ \),\( \ 0,8)\), also eine Verteilung, bei der alle Werte von \(x\) innerhalb des Intervalls \([-2 \ \),\( \ 0,8] \) gleich \( \frac{1}{b-a}(=\frac{1}{0,8-(-2)}\approx 0,36)\) sind, während alle anderen Werte von \(x\) gleich \(0\) sind.
x = np.linspace(-4.2, 4.2, num=1000)
fig, ax = plt.subplots()
ax.plot(x, uniform.pdf(x, -2, 2 + 0.8), linewidth=4)
ax.set_title(r"$X \sim U(-2, 0.8)$")
ax.set_ylabel("Wahrscheinlichkeitsdichte")
Text(0, 0.5, 'Wahrscheinlichkeitsdichte')
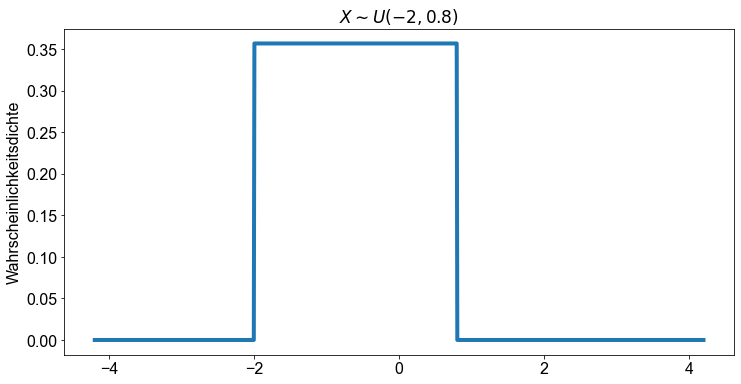
Der Mittelwert und der Median sind gegeben durch
Die kumulative Dichtefunktion ist unten dargestellt und ergibt sich aus der Gleichung
x = np.linspace(-4.2, 4.2, num=1000)
fig, ax = plt.subplots()
ax.plot(x, uniform.cdf(x, -2, 2 + 0.8), linewidth=4)
ax.set_title(r"$X \sim U(-2, 0.8)$")
ax.set_ylabel("Kummulierte Wahrscheinlichkeitsdichte")
Text(0, 0.5, 'Kummulierte Wahrscheinlichkeitsdichte')
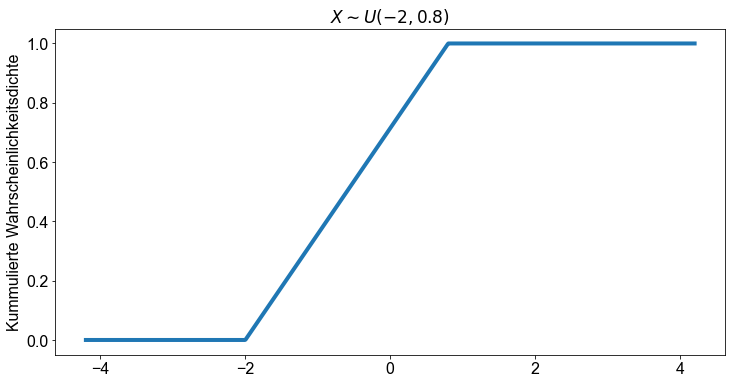
Die kontinuierliche gleichmäßige Verteilung in Python¶
Python ermöglicht den Zugriff auf die Gleichverteilung mit den Funktionen uniform.pmf(), uniform.cdf(), uniform.ppf() und uniform.rvs(). Wenden Sie die Funktion dir() auf diese Funktionen an, um weitere Informationen zu erhalten.
Die Funktion uniform.rvs() erzeugt Zufallsabweichungen der Gleichverteilung und wird als uniform.rvs(loc, loc+scale, size) geschrieben. Wir können auf einfache Weise \(n\) Zufallsstichproben innerhalb eines beliebigen Intervalls erzeugen indem wir die Zahlenwerte für minimalen (\(a\)) und maximalen Wert (\(b\)) in random.uniform(a,b, size) einsetzen.
u_rvs = np.random.uniform(-1, 1, size=40)
u_rvs
array([ 0.51099129, 0.68180268, 0.67820609, -0.45282383, -0.83192511,
-0.89807062, 0.90987702, -0.07300471, -0.10907998, -0.36033233,
0.64378893, -0.35998136, -0.25800605, -0.05718817, -0.88117942,
0.76535448, 0.99054007, -0.57656593, 0.13046694, -0.92921365,
-0.37308738, -0.36064957, -0.54931976, -0.26662623, 0.22134615,
-0.75559623, -0.79613785, 0.84372686, -0.94805424, 0.88807796,
-0.79712861, -0.24142211, 0.87557899, 0.50996594, -0.70976085,
-0.80289702, 0.54355605, 0.49939617, 0.51719347, -0.62152339])
Wir können die Dichtefunktion für \(X \sim U(-2 \ \),\( \ 0,8)\) mit Hilfe der Funktion uniform.rvs() approximieren und die Ergebnisse als Histogramm darstellen.
# Erzeuge gleichverteilte werte
u_rvs = np.random.uniform(-2, 0.8, size=10000)
# Plotte Histogramm
fig, ax = plt.subplots()
ax.set_xlim(-3, 3)
ax.set_title("Histogramm für rand.uniform")
ax.set_ylabel("Wahrscheinlichkeitsdichte")
ax.hist(u_rvs, bins=20, edgecolor="k")
(array([453., 519., 507., 482., 519., 522., 522., 495., 482., 500., 492.,
495., 578., 478., 481., 452., 490., 497., 521., 515.]),
array([-1.99994748, -1.85996899, -1.7199905 , -1.58001201, -1.44003352,
-1.30005503, -1.16007654, -1.02009805, -0.88011956, -0.74014107,
-0.60016258, -0.46018409, -0.32020561, -0.18022712, -0.04024863,
0.09972986, 0.23970835, 0.37968684, 0.51966533, 0.65964382,
0.79962231]),
<BarContainer object of 20 artists>)
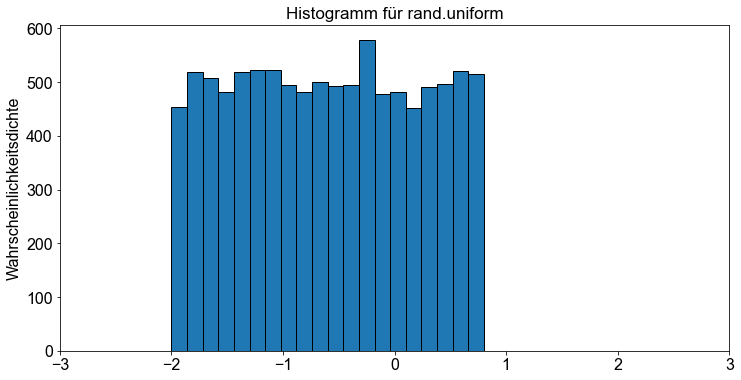
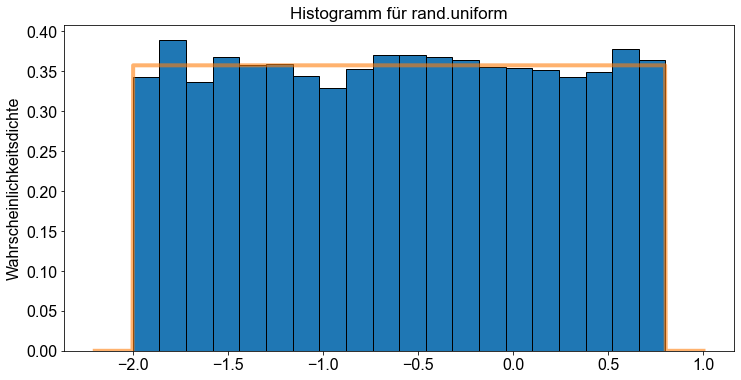
Außerdem stellen wir sowohl das Dichtehistogramm von oben als auch die gleichmäßige Wahrscheinlichkeitsverteilung für das Intervall \([-2 \ \),\( \ 0,8]\) dar, indem wir die Funktion uniform.pdf() anwenden.
# Erzeuge x-werte
x = np.linspace(-2.2, 1, num=1000)
# Erzeuge gleichverteilte werte
u_rvs = uniform.rvs(loc=-2, scale=2 + 0.8, size=10000)
# Plotte Histogramm und uniforme pdf
fig, ax = plt.subplots()
ax.set_title("Histogramm für rand.uniform")
ax.set_ylabel("Wahrscheinlichkeitsdichte")
ax.hist(u_rvs, bins=20, edgecolor="k", density=True)
ax.plot(x, uniform.pdf(x, -2, 2 + max(u_rvs)), linewidth=4, alpha=0.6)
[<matplotlib.lines.Line2D at 0x16d62c2b0>]
unif_mean = (-2 + 0.6) / 2
unif_mean
-0.7
Die Abbildung zeigt, dass unsere \(10.000\) Stichproben, die nach dem Zufallsprinzip aus einer Gleichverteilung gezogen wurden (Histogramm), sich der Gleichverteilung \(X \sim U(-2 \ \),\( \ 0,8)\) (Liniendiagramm).
Außerdem können wir die Funktion uniform.cdf() verwenden, um die Fläche unter der Kurve für einen bestimmten Schwellenwert zu berechnen, oder wir können die Funktion uniform.ppf() verwenden, um einen Schwellenwert für eine bestimmte Wahrscheinlichkeit zurückzugeben.
Übung¶
Betrachten wir die gleichmäßige Wahrscheinlichkeitsverteilung, die durch \(X \sim U(-3 \ \),\( \ 5,5)\) gegeben ist.
Frage 1
Wie lautet der Mittelwert \(\mu\) für die gegebene Gleichverteilung.
unif_mean = (-3 + 5.5) / 2
unif_mean
1.25
Der Mittelwert \(\mu\) für die durch \(X \sim U(-3 \ \),\( \ 5,5)\) gegebene gleichmäßige Wahrscheinlichkeitsverteilung beträgt \(1,25\).
Frage 2
Welcher Wert von \(x\) entspricht dem Wert, der die gegebene Gleichverteilung in zwei gleiche Teile teilt, oder anders ausgedrückt: \(P(X \lt ?)=0,5\).
p_50 = uniform.ppf(0.5, -3, 8.5)
p_50
1.25
Das ist überhaupt keine Überraschung. Der Wert von \(x\), der die Gleichverteilung in zwei gleiche Teile teilt, beträgt \(1,25\) und ist somit gleich \(\mu\).
Frage 3
Angenommen, die obige Verteilung beschreibt ein physikalisches Phänomen. Wie groß ist die Wahrscheinlichkeit, dass bei einer Messung des physikalischen Prozesses, der das Phänomen bestimmt, ein Wert \(\ge 4\) gemessen wird, oder anders ausgedrückt: \(P(X \ge 4)\). Aufgrund des Charakters einer Gleichverteilung ist die Messung eines beliebigen Wertes innerhalb des Intervalls \([-3 \ \),\( \ 5,5]\) gleich wahrscheinlich ist.
Wir werden diese Frage auf zwei Arten lösen, numerisch und analytisch. Um die Frage numerisch zu lösen, müssen wir zunächst ein Experiment durchführen. Wir wiederholen unsere Messung eine große Anzahl von Malen und zählen dann, wie oft wir einen Wert \(\ge 4\) registriert haben
. Dank der Leistungsfähigkeit von Python und dem integrierten Zufallszahlengenerator uniform.rvs() für gleichmäßig verteilte Daten) ist die Wiederholungsaufgabe sehr einfach, allerdings sollte man sich darüber im Klaren sein, dass in realen Anwendungen oft nur eine sehr begrenzte Anzahl von Messungen verfügbar ist.
# Erzeuge gleichverteilte Zufallsvariablen und Variable count
u_rvs = uniform.rvs(-3, 8.5, size=10000)
# Zähle Werte größer gleich 4
count = sum(u_rvs >= 4)
# Dividiere durch Gesamtanzahl der Werte
count = count / len(u_rvs)
count
0.1766
Die Ergebnisse zeigen, dass etwa \(18 \%\) der Messungen Werte \(\ge 4\) ergeben.
Zweitens, um die Frage analytisch zu lösen, verwenden wir die kumulative Wahrscheinlichkeitsdichtefunktion, die in Python für gleichmäßige Verteilungen durch die Funktion uniform.cdf() implementiert ist.
Wir interessieren uns also für die Fläche unter der Kurve bis zum Wert von \(x=4\).
1 - uniform.cdf(4, -3, 8.5)
0.17647058823529416
Der analytische Ansatz ergibt ein Ergebnis von \(0,1764706\) oder anders ausgedrückt, mit einer Wahrscheinlichkeit von \(17,65 \%\) erhalten wir Werte \(\ge 4\), also \(P(X \ge 4) \approx 0,18\).
Es ist offensichtlich, dass beide Ansätze sehr ähnliche Ergebnisse liefern. Es ist jedoch zu beachten, dass das Ergebnis des numerischen Ansatzes eine Annäherung an das analytische Ergebnis darstellt. Bedenken Sie, dass die Qualität einer solchen Annäherung sehr stark von der Anzahl der Zufallsvariablen abhängt, aus denen die Stichprobe besteht, in unserem Fall von der Anzahl der Messungen.