Polynomiale Regression
Contents
Polynomiale Regression¶
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
from sklearn.metrics import mean_squared_error
import statsmodels.api as sm
Die polynomiale Regression ist eine spezielle Art der linearen Regression, bei der die Beziehung zwischen der unabhängigen Variablen \(x\) und der abhängigen Variablen \(y\) durch ein Polynom \(n\)-ten Grades in \(x\) modelliert wird. Mit anderen Worten, wir nehmen neben dem ursprünglichen linearen Term auch Potenzen zweiter Ordnung und höherer Potenzen einer Variablen in das Modell auf. Die Einbeziehung von Polynomen \(n\)-ten Grades führt zu einer nichtlinearen Beziehung zwischen \(y\) und \(x\), aber das Modell ist immer noch ein lineares Modell, da die Beziehung zwischen den Koeffizienten (\(\beta_i\)) und den erwarteten Beobachtungen linear ist. Somit kann die Modellgleichung wie folgt geschrieben werden
Die Werte der Koeffizienten werden durch Anpassung des Polynoms an die Beobachtungsdaten (\(y\)) bestimmt. Wie bei der einfachen linearen Regression, die im vorigen Abschnitt behandelt wurde, geschieht dies durch Minimierung der Summe der quadrierten Fehler (\(SSE\)), die durch folgende Gleichung gegeben ist
Bei der Anpassung eines Polynoms an Beobachtungen stellt sich das Problem der Wahl der Ordnung \(k\) des Polynoms. Wie man die richtige Zahl für das Polynom wählt, ist eine Frage eines wichtigen Konzepts, das Modellauswahl oder Informationskriterium genannt wird. Der Einfachheit halber verwenden wir die Wurzel des mittleren quadratischen Fehlers (root-mean-square error, RMSE), definiert durch
um die Eignung des Modells zu bewerten.
Polynomiale Regression¶
Wir beginnen mit unserer Übung, indem wir Daten sammeln. Die Daten werden von einer Funktion generiert, die Sie nicht kennen. Diese Vorbedingung macht das Beispiel realistischer, da wir in realen Anwendungen die genauen Spezifikationen des zugrunde liegenden Datenerzeugungsprozesses nicht kennen. Am Ende dieses Abschnitts lüften wir das Geheimnis des Datengenerierungsprozesses.
Dies sind die Daten, unsere Beobachtungen, in tabellarischer Form. Wir haben \(25\) Datenpunkte, jeder Datenpunkt ist ein (\(x,y\)) Paar.
n = 25
np.random.seed(4)
x = np.random.uniform(0, 1, n)
y = np.sin(2 * np.pi * x) + np.random.normal(0, 0.35, n)
poly_data = pd.DataFrame({"x": x, "y": y})
Hier sind die Daten in Form eines Streudiagramms dargestellt:
fig, ax = plt.subplots()
X = poly_data["x"]
y = poly_data["y"]
ax.scatter(X, y, edgecolor="k", color="white")
ax.set_xlabel("x")
ax.set_ylabel("y")
Text(0, 0.5, 'y')
Anpassen einer Kurve in Python: Die Notation in Python¶
Python bietet leistungsstarke Funktionen zur Anpassung eines Polynoms an Daten. Um ein \(k\)-dimensionales Polynom anzupassen, verwenden wir linear_model aus dem sklearn Paket und fügen dem Funktionsaufruf LinearRegression() zusätzliche PolynomialFeatures hinzu. Darüber hinaus gibt es zwei verschiedene Möglichkeiten, eine polynomiale Regression zu kodieren.
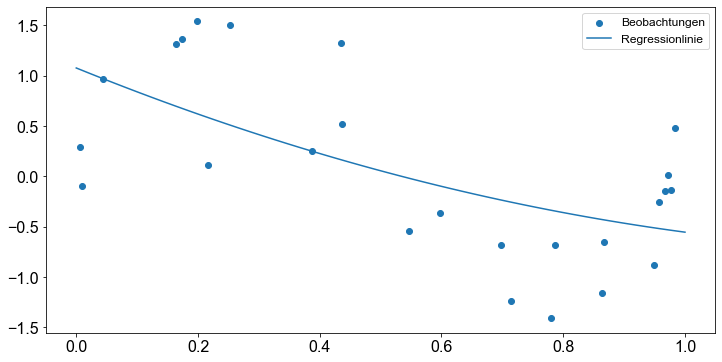
Für ein Polynom \(2\). Ordnung besteht die erste Möglichkeit darin, model.predict(X-werte) einzugeben und zu plotten, und die zweite Möglichkeit ist die Koeffizienten mit model.coef_ aus dem Model auszulesen und daraus äquivalent zu \(\hat y = \beta_0+\beta_1x+\beta_2x^2+...+\beta_kx^k+\epsilon\) , model.coef_[0][0] + model.coef_[0][1] * X-werte + model.coef_[0][2] * (X-werte)**2 + ... zu konstruieren.
Um die Verwirrung zu lindern, zeigen wir ein Beispiel in Python. Wir konstruieren zwei Polynome der Ordnung \(2\) für poly_data.
X = poly_data["x"].values.reshape(-1, 1)
y = poly_data["y"].values.reshape(-1, 1)
# Polynomialer Fit
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
model = LinearRegression()
model.fit(X_poly, y)
LinearRegression()
Zum Auslesen der Koeffizienten und des Achsenabschnitts des Modells verwenden wir das Attribut coef_ und intercept_.
Wir überprüfen die Ergebnisse des Modells.
print(f"Achsenabschnitt: {model.intercept_}")
print(f"Koeffizienten: {model.coef_}")
Achsenabschnitt: [1.07678298]
Koeffizienten: [[ 0. -2.45381544 0.82240915]]
Bei der Ausgabe der Koeffizienten dient der nullte Koeffizient als Platzhalter für den Achsenabschnitt und kann daher ignoriert werden. Setzen wir nun die Parameter in die Gleichung ein, erhalten wir die Regressionslinie.
# Definiere x- Achse zur Vorhersage von Datenpunkten
x_axis = np.linspace(0, 1, 50)
# Konstruiere Regressionslinie
regline = (
model.intercept_ + model.coef_[0][1] * x_axis + model.coef_[0][2] * x_axis**2
)
fig, ax = plt.subplots()
ax.scatter(poly_data["x"], poly_data["y"], label="Beobachtungen")
ax.plot(x_axis, regline, label="Regressionlinie")
ax.legend()
<matplotlib.legend.Legend at 0x170cbd5a0>
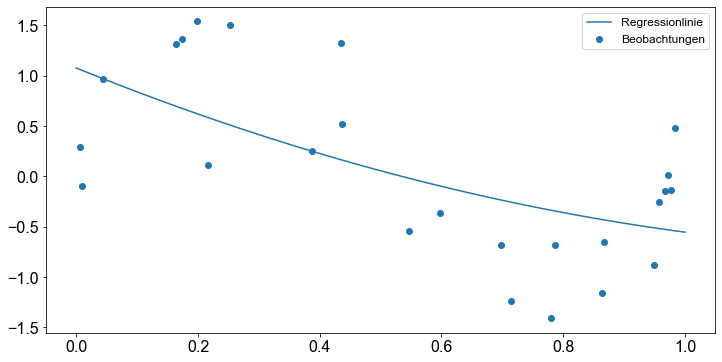
Andererseits können wir die Regressionslinie auch mit der Methode predict() für beliebige \(x\)-Werte erzeugen.
X_poly = poly.transform(x_axis.reshape(-1, 1))
regline = model.predict(X_poly)
fig, ax = plt.subplots()
ax.plot(x_axis, regline, label="Regressionlinie")
ax.scatter(x=X, y=y, label="Beobachtungen")
ax.legend()
<matplotlib.legend.Legend at 0x170ec31c0>
Anpassen einer Kurve in Python (Fortsetzung)¶
Da wir nun die Notation in Python kennen, beginnen wir mit der Erstellung von \(6\) verschiedenen Modellen, mit \(k=1,2,3,5,9,12\). Für jedes Modell berechnen wir den \(RMSE\). Schließlich stellen wir die Daten zusammen mit der Regressionslinie dar, die durch jedes einzelne Modell gegeben ist. Der Einfachheit halber konstruieren wir eine Schleife, um den Kodierungsaufwand zu verringern.
RMSE = []
X = poly_data["x"].values.reshape(-1, 1)
y = poly_data["y"].values.reshape(-1, 1)
x_axis = np.linspace(0, 1, 25)
orders = [1, 2, 3, 5, 9, 12]
fig, ax = plt.subplots(figsize=(16, 18), ncols=2, nrows=3)
ax = np.ravel(ax)
for e, order in enumerate(orders):
poly = PolynomialFeatures(degree=order)
X_poly = poly.fit_transform(X)
model = LinearRegression()
model.fit(X_poly, y)
y_hat = model.predict(X_poly)
mse = mean_squared_error(y, y_hat)
rmse = np.sqrt(mse)
RMSE.append(rmse)
X_poly = poly.transform(x_axis.reshape(-1, 1))
regline = model.predict(X_poly)
ax[e].plot(x_axis, regline, label=f"Regressionslinie der {order}. Ordnung")
ax[e].scatter(x=X, y=y, label="Beobachtungen")
ax[e].text(s=f"RMSE (k={order}): {np.round(rmse, 4)}", y=0.8, x=0.5, size=18)
ax[e].legend()
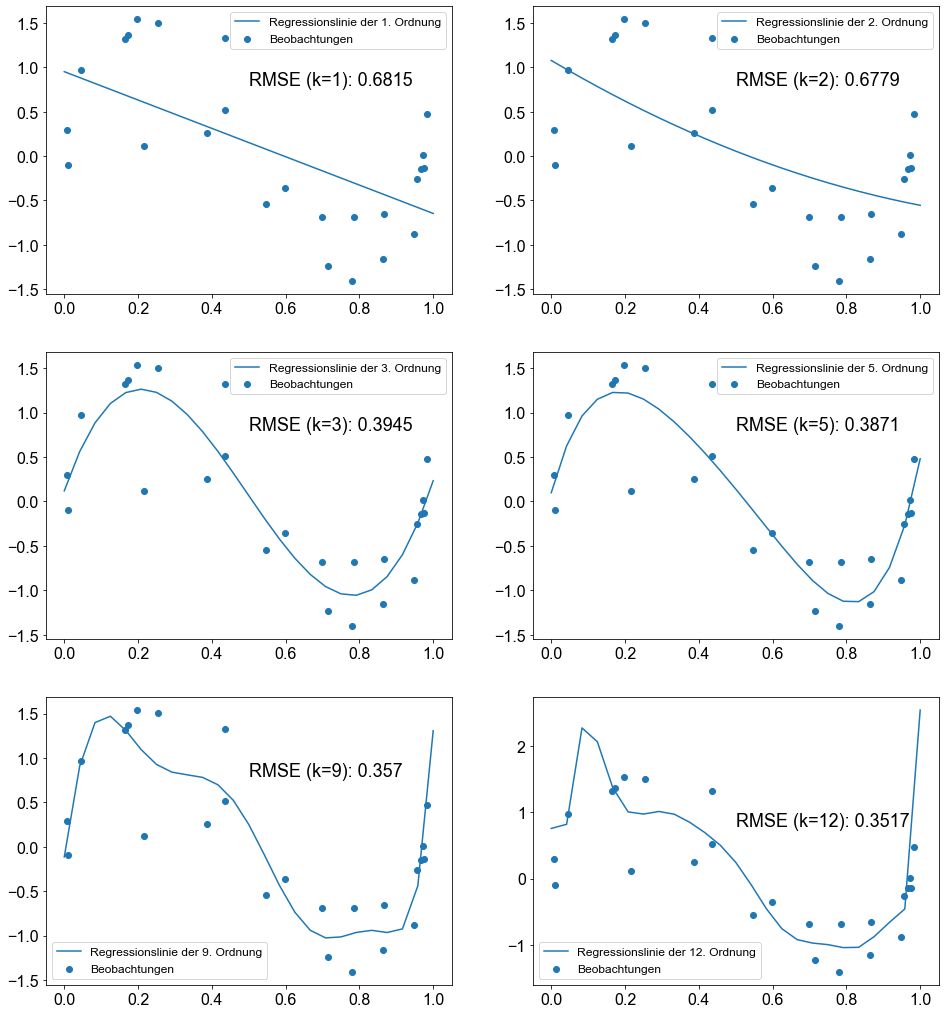
Fantastische Diagramme! Die Abbildung zeigt, dass wenn wir \(k\), die Ordnung des Polynoms, erhöht, wird die Kurve flexibler und passt immer besser zu den Daten. Je besser die Daten angepasst werden, desto geringer wird der Fehler, \(RMSE\).
Der Einfachheit halber plotten wir den \(RMSE\) gegen \(k\).
fig, ax = plt.subplots()
ax.plot(orders, RMSE)
ax.set_ylabel("RMSE")
ax.set_xlabel("k-te Ordnung")
Text(0.5, 0, 'k-te Ordnung')
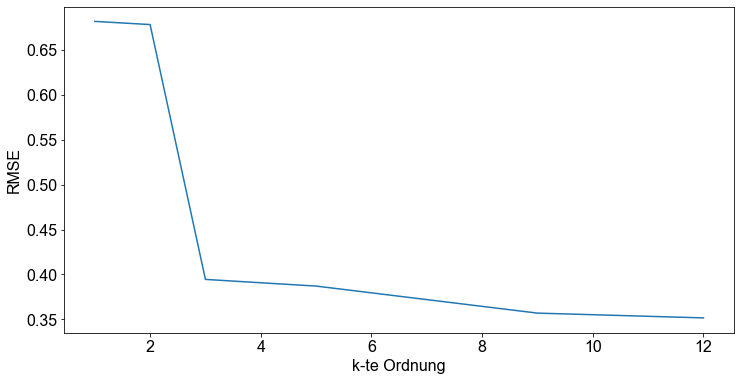
Daher stellt sich wieder einmal die Frage, welches Polynom am besten zu den Daten passt. Glauben wir, dass das Polynom der Ordnung \(9\) am besten zu dem zugrunde liegenden Datenerzeugungsprozess passt? Obwohl wir eine hervorragende Anpassung an die Beobachtungsdaten erhalten, indem wir die Ordnung des Polynoms erhöhen, bleibt es fraglich, ob das Polynom hoher Ordnung gut verallgemeinert werden kann. Stellen Sie sich vor, wir führen eine neue Messreihe durch und erhalten neue Daten. Glauben Sie, dass die wild schwingende Kurve eines Polynoms hoher Ordnung immer noch gut zu den Daten passt? Nein, wahrscheinlich nicht!
Dieses Verhalten wird als Überanpassung bezeichnet. Erinnern Sie sich daran, dass das Ziel darin besteht, die Parameter aus den Daten zu lernen. Wir sind also daran interessiert, eine gute Verallgemeinerung des Modells zu erreichen und nicht unbedingt perfekt angepasste Beobachtungsdaten.
Aus den Daten lernen¶
Wie können wir das Problem lösen? Wie bestimmen wir das beste Polynom \(n\)-ter Ordnung für unseren Datensatz? Nun, es gibt viele Methoden und Strategien, um einer Überanpassung entgegenzuwirken. In diesem Abschnitt verfolgen wir einen einfachen Ansatz. Zunächst teilen wir den Datensatz in zwei Teile auf. Einen Teil nennen wir Trainingsmenge, den anderen Teil nennen wir Validierungsmenge. Dann verwenden wir alle Daten des Trainingssatzes, um die Modellparameter \(\beta_i\) zu lernen, und zwar auf die gleiche Weise wie oben. Danach wenden wir das gelernte Modell an, um die Daten des Validierungssatzes vorherzusagen, und bewerten die Leistung des Modells, indem wir den \(RMSE\) berechnen. Wir verwenden also die Validierungsmenge, um die, durch \(k\) gegebene, Komplexität des Modells zu optimieren.
Leider brauchen wir, wenn wir aus Daten lernen wollen, letztendlich auch Daten, aus denen wir lernen können. Bislang haben wir mit \(25\) Beobachtungen gearbeitet. Das ist nicht viel. In realen Anwendungen müssten wir wahrscheinlich neue Beobachtungen durch eine neue Messreihen gewinnen. In unserer Übung können wir jedoch relativ leicht mehr Daten erzeugen. Daher setzen wir dieses Beispiel mit einem neuen Datensatz von \(150\) Beobachtungen fort.
Lassen Sie uns die Daten plotten!
n = 150
np.random.seed(415)
x = np.random.uniform(0, 1, n)
y = np.sin(2 * np.pi * x) + np.random.normal(0, 0.3, n)
new_poly_data = pd.DataFrame({"x": x, "y": y})
new_poly_data.plot.scatter(x="x", y="y")
<AxesSubplot:xlabel='x', ylabel='y'>
Trainings- und Validierungsmenge¶
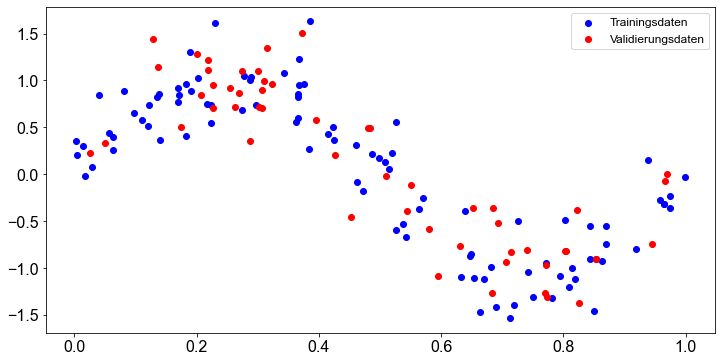
Nun sind wir bereit, unsere Trainings- und Validierungsmenge zu erstellen. Dazu verwenden wir die Funktion train_test_split() aus dem sklearn-Paket. Wir teilen die Daten so auf, dass \(65 \%\) der Daten dem Trainingsset und der Rest, \(35 \%\) der Daten, dem Validationsset zugewiesen werden.
X = new_poly_data.x.values.reshape(-1, 1)
y = new_poly_data.y.values.reshape(-1, 1)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.35, random_state=42)
# Überprüfen der Dimension von Training und Validierungsdatensatz
print("Trainingset")
print(f"X_train: {np.shape(X_train)}")
print(f"y_train: {np.shape(y_train)}")
print("\nValidierungsset")
print(f"X_val: {np.shape(X_val)}")
print(f"y_val: {np.shape(y_val)}")
Trainingset
X_train: (97, 1)
y_train: (97, 1)
Validierungsset
X_val: (53, 1)
y_val: (53, 1)
# Plot
plt.scatter(X_train, y_train, label="Trainingsdaten", color="blue")
plt.scatter(X_val, y_val, label="Validierungsdaten", color="red")
plt.legend()
<matplotlib.legend.Legend at 0x1711e8160>
Modellbildung und Modellbewertung¶
In dieser Übung werden wir \(10\) Modelle mit \(k=1,2,...,10\) erstellen. Wir bewerten jedes der \(10\) polynomialen Regressionsmodelle, indem wir den \(RMSE\) auf dem Trainingssatz berechnen. Nach der Erstellung des Modells und der Ermittlung der Modellparameter \(\beta_i\) verwenden wir das Modell, um die Antwortvariable in der Validierungsmenge vorherzusagen. Auch hier stützen wir uns auf den \(RMSE\), um die Vorhersagen für den Validierungssatz zu bewerten. Schließlich stellen wir den \(RMSE\) jedes Modells sowohl für die Trainingsmenge als auch für die Validierungsmenge dar. Anhand des \(RMSE\) bewerten wir die Generalisierung des Modells.
rmse_train = []
rmse_val = []
for order in range(1, 11):
# Polynomial Fit
poly = PolynomialFeatures(degree=order)
X_train_poly = poly.fit_transform(X_train) # .reshape(-1, 1)
X_val_poly = poly.fit_transform(X_val) # .reshape(-1, 1)
model = LinearRegression()
model.fit(X=X_train_poly, y=y_train)
# Berechne RMSE - Trainingsset
mse = mean_squared_error(y_train, model.predict(X_train_poly))
rmse = np.sqrt(mse)
print(f"RMSE train (k={order}): {np.round(rmse,3)}")
rmse_train.append(rmse)
# Berechne RMSE - Validierungsset
mse = mean_squared_error(y_val, model.predict(X_val_poly))
rmse = np.sqrt(mse)
print(f"RMSE val (k={order}): {np.round(rmse,3)}")
rmse_val.append(rmse)
print("------------------------")
RMSE train (k=1): 0.554
RMSE val (k=1): 0.539
------------------------
RMSE train (k=2): 0.553
RMSE val (k=2): 0.538
------------------------
RMSE train (k=3): 0.312
RMSE val (k=3): 0.324
------------------------
RMSE train (k=4): 0.306
RMSE val (k=4): 0.329
------------------------
RMSE train (k=5): 0.284
RMSE val (k=5): 0.344
------------------------
RMSE train (k=6): 0.282
RMSE val (k=6): 0.346
------------------------
RMSE train (k=7): 0.282
RMSE val (k=7): 0.345
------------------------
RMSE train (k=8): 0.282
RMSE val (k=8): 0.345
------------------------
RMSE train (k=9): 0.282
RMSE val (k=9): 0.345
------------------------
RMSE train (k=10): 0.282
RMSE val (k=10): 0.345
------------------------
k = range(1, 11)
fig, ax = plt.subplots()
ax.plot(k, rmse_train, label="Trainingsset", color="blue")
ax.plot(k, rmse_val, label="Validierungsset", color="red")
ax.set_ylabel("RMSE")
ax.set_xlabel("k-te Ordnung")
ax.legend()
<matplotlib.legend.Legend at 0x1713b6aa0>
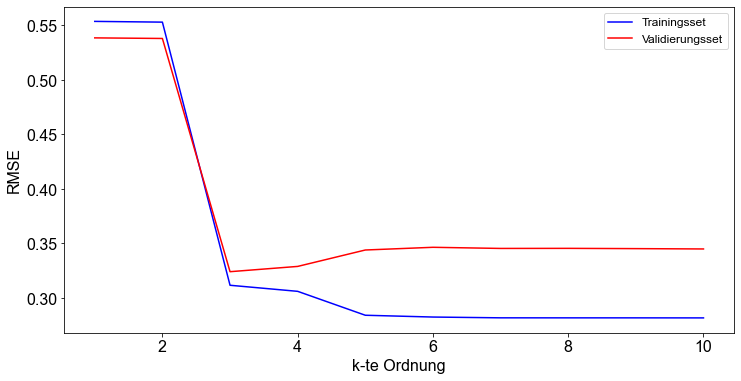
Die Abbildung zeigt, dass der Fehler bei den Trainingsdaten (blaue Linie) stetig abnimmt. Das macht durchaus Sinn, denn je komplexer das Modell wird, indem \(k\) erhöht wird, desto besser passt das Modell zu den Trainingsdaten. Das gleiche Verhalten haben wir im obigen Abschnitt beobachtet, als wir unser Modell mit nur \(25\) Beobachtungen trainiert haben. Wenn wir uns den \(RMSE\) für den Validierungssatz (rote Linie) ansehen, sehen wir, dass mit zunehmendem \(k\) und damit zunehmender Modellkomplexität der Fehler abnimmt. Es gibt jedoch einen “Sweet Spot”, der durch den niedrigsten \(RMSE\) angezeigt wird, an dem das Modell gerade komplex genug ist, um auf den bisher ungesehenen Validierungsdaten gut zu generalisieren. Wenn die Modellkomplexität weiter zunimmt, beginnt auch der \(RMSE\) zu steigen. Dies deutet auf eine Überanpassung des Modells hin. Das Modell merkt sich also die Daten in der Trainingsmenge gut, aber die Vorhersagekraft des Modells für bisher ungesehene Daten, wie die Daten der Validierungsmenge, wird schlechter. Ein Blick auf die obige Abbildung zeigt, dass der niedrigste Fehler im Validierungssatz, der so genannte Sweet Spot, für ein Regressionsmodell \(3\)-ter Ordnung erreicht wird.
Vorstellung des Modells¶
Im vorangegangenen Abschnitt haben wir festgestellt, dass ein polynomiales Regressionsmodell der Ordnung \(3\) in der Validierungsgruppe am besten funktioniert. Nun stellen wir dieses Modell auf dem gesamten Datensatz dar, um seine Qualität visuell zu bewerten. Außerdem stellen wir die Funktion dar, die dem Prozess der Datengenerierung zugrunde liegt.
Datenerzeugung: Die Eingabewerte \(x_n\) für die zugrundeliegende Funktion werden gleichmäßig im Bereich \(U(0,1)\) erzeugt, und die entsprechenden Zielwerte \(y\) erhält man, indem man zunächst die entsprechenden Werte der Funktion \(\sin( \pi x )\) berechnet und dann zufälliges Rauschen mit einer Gaußschen Verteilung mit einer Standardabweichung von \(0,35\) hinzufügt.
# Erzeuge Daten
n = 100
np.random.seed(4)
x = np.random.uniform(0, 1, n)
y = np.sin(2 * np.pi * x) + np.random.normal(0, 0.35, n)
raw_data = pd.DataFrame({"x": x, "y": y})
X = raw_data["x"].values.reshape(-1, 1)
y = raw_data["y"].values.reshape(-1, 1)
# Polynomial Fit
poly = PolynomialFeatures(degree=3)
X_poly = poly.fit_transform(X)
model = LinearRegression()
model.fit(X_poly, y)
x_axis = np.linspace(0, 1, 150)
x_axis_poly = poly.fit_transform(x_axis.reshape(-1, 1))
y_reg_line = model.predict(x_axis_poly)
fig, ax = plt.subplots()
ax.scatter(X, y, label="Stichprobe")
ax.plot(x_axis, y_reg_line, label="Regressionslinie")
ax.plot(x_axis, np.sin(2 * np.pi * x_axis), label="Datenerzeugungsfunktion")
ax.legend()
<matplotlib.legend.Legend at 0x171311090>
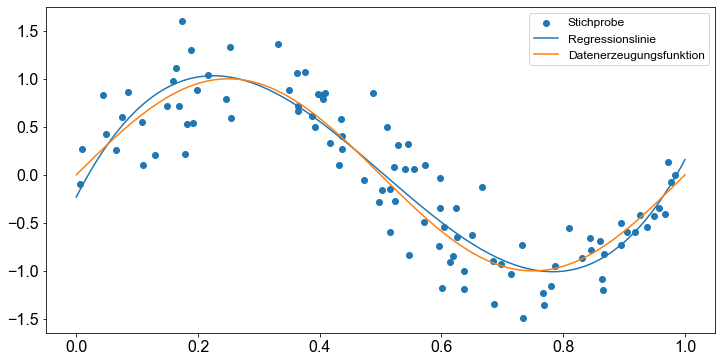
Die Abbildung zeigt, dass unser Modell die Daten gut abbildet und wir daher recht zufrieden damit sein können.